11.18.Configuration of File system recovery job
File system recovery jobs are used to re-generate a file system from the archive back into the original file location. This processing type can be used in the following cases:
- The entire folder structure has been deleted;
- One or more folders have been deleted;
- One or more documents from the folder(s) have been deleted and the user needs to get back these already archived documents from the archive.
The file system recovery is able to reconstruct the entire folder structure from the archive: the items that have been already archived will be put back into their source location. It will also create the folder if it was deleted from the folder structure. It is possible to recover any part of the structure:
- One or multiple folders;
- Recursive folder structure;
- One or more folder contents.
The file system recovery job is checking for the duplicates, so the same recovery job can be run safely multiple times, duplicates will not be created:
- If there is a shortcut for the recovered file in the folder – the file won’t be recovered;
- If the file is already present in the folder – the file won’t be recovered;
- If the same file is archived multiple times into the same folder – only the youngest file will be recovered.
The user has multiple options what to recover; it is possible to recover either the original file or the shortcut. The recovery job can be also used if the user archived the files with the “delete” method and these files should be put back into the file system.
To create a recovery job, navigate to File Archive ⇒ Archive ⇒ Jobs control button and click on +new. In the Add new job instance dialog, select File system recovery job from the dropdown list, select a node where the job should run from the Run on node dropdown list (if you would not like to specify a node here and the job should run on any available node, then select “Any available”), enter a Display name and click on Add.
✓ Scheduling settings:
In this step the running times of the recovery job must be selected. It is possible either to select a scheduler from the list or to create a new scheduler via create new option. Recovery jobs are run only in specific cases. In most of the cases it is recommended to set a One time scheduler for the recovery job (e.g. with start date 7th of September at 6 PM), or to start the job manually from the status bar. (For more information about how to set schedulers refer to the section Schedules above.)
✓ Processing settings:
There are two possibilities what to recover by the job: the user may recover either the original, or the shortcut. If the user selects the shortcutting option, it is also required to specify the Virtual drive server name. By using the “Use default” option, the Virtual Drive that was already configured on the Virtual Drive configuration page will be automatically preselected. It is recommended to use this option, because if the settings are changed on the Virtual Drive configuration page, the value will be automatically used by the job, too, without a need to change the job’s settings.
✓ Folders to process:
In this section the user is required to specify one or multiple archive folder(s), or recursive folder structure(s) that were deleted and need to be recovered from the archive. There are multiple options how to add new source location(s) with content needed to be recovered:
- Via the + new option:
Click + new. The Folder to process dialog will open. In our case the contents of the “invoices” folder (file path \tanewsTECH-ARROW files to archiveinvoices) was originally archived and deleted, and we need to receive these documents back from the archive. First, we select the Root file path from the dropdown list and enter the subfolder to the Relative path text box.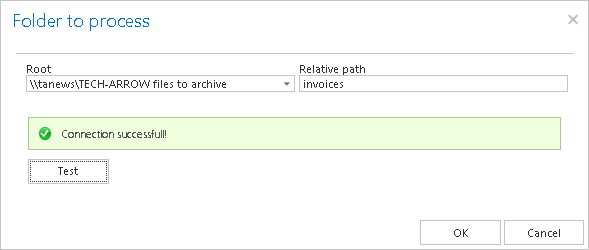
- It is also possible to import the files to recover from a file, where the file path(s) are specified. To import this file, click the “import” button and follow the steps specified in chapter Importing contentACCESS configurations from files of this guide.
✓ Exclude folders
With this function you may set, which folders/subfolders should not be recovered. The same rules apply for these settings is in the file archive job. If you would not like to exclude any folder from the recovery process, you can skip these settings.
The folders may be excluded using one of the available methods: a) They may be added manually via the + new option; b) or may be imported in one of the available file formats via the import option.
- Add exclude folders manually:
Click on + new option. In the Exclude folder dialog’s textbox specify the folder(s) to be excluded. Use the hints that are featured in the same dialog.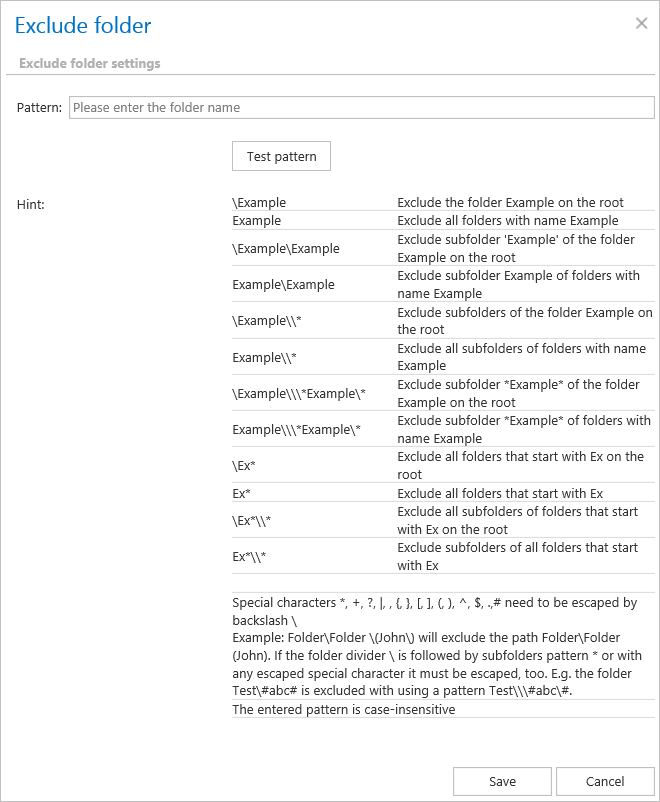
- Import the list of exclude folders:
Exclude folders may be imported as files in one of the available formats: CSV, XML, Tab delimited files or Space delimited file. The file to be imported must contain the list of folders. To import such a file with the list of folders refer to chapter Importing contentACCESS configurations from files of this guide.
✓ Modification date
The files can be recovered either with the original modification date or with the recovery date. It is recommended to set the recovery date if the folder is already processed by an archive job and the user wants to prevent the folder from re-archiving.
✓ Notification settings:
The user may select here, in which cases he needs to get notifications from the recovery job. It is possible to set here that the notification emails will be sent only in case of errors or warnings, or they can be sent in all cases, too. Into the Recipient list textbox the user should insert the email addresses of the people, whom these emails should be sent to. Notifications emails may be used as tools of the troubleshooting process.
✓ Resource settings:
The user may set a value here, which will determine how many items will be processed simultaneously by the recovery job.